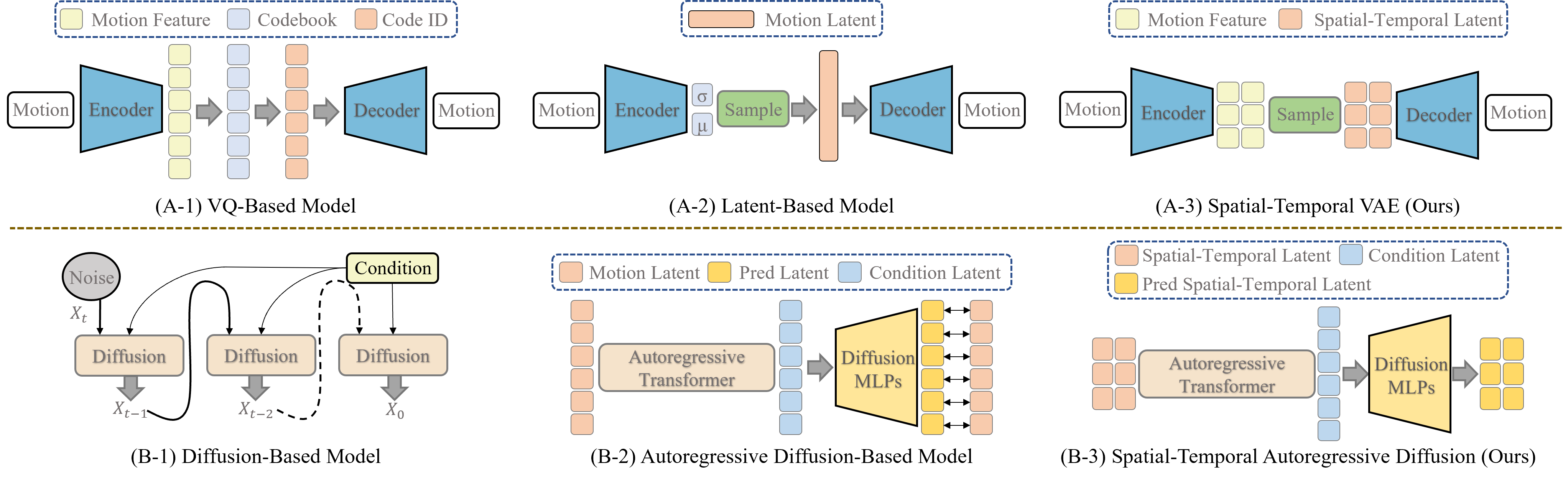
Text-driven human motion synthesis has made substantial development with two core modules of motion representation and generative architecture. For representation, Vector Quantization (VQ)-based methods compress motion data into discrete tokens while latent-based models operate directly in continuous space. However, both of these representations exhibit significant limitations. VQ-based methods suffer from inherent information loss, which compromises the quality, diversity, and generalization of generated motions, while continuous representation on holistic whole-body motion hinders part-level flexibility. For architecture, diffusion and autoregressive diffusion models have demonstrated their superiority, yet the fine-grained controllability over individual body parts is also limited.
To overcome the aforementioned issues, we propose a unified spatiotemporally decoupled framework named DeMoDiff, which jointly redesigns representation and architecture. First, we propose a lightweight spatial-temporal VAE that encodes each body joint rather than compressing the whole-body motion into a single latent space. The decoupled paradigm substantially enhances representation extraction capabilities and offers greater part-level controllability. Second, we incorporate spatial-temporal masking and attention mechanisms into an autoregressive diffusion generator, achieving both generative capability and controllable editability.
Extensive experiments on the HumanML3D and KIT-ML datasets demonstrate that our model achieves state-of-the-art reconstruction performance and compelling motion generation results. Moreover, our framework demonstrates strong temporal and spatial editing capabilities, further validating its effectiveness.
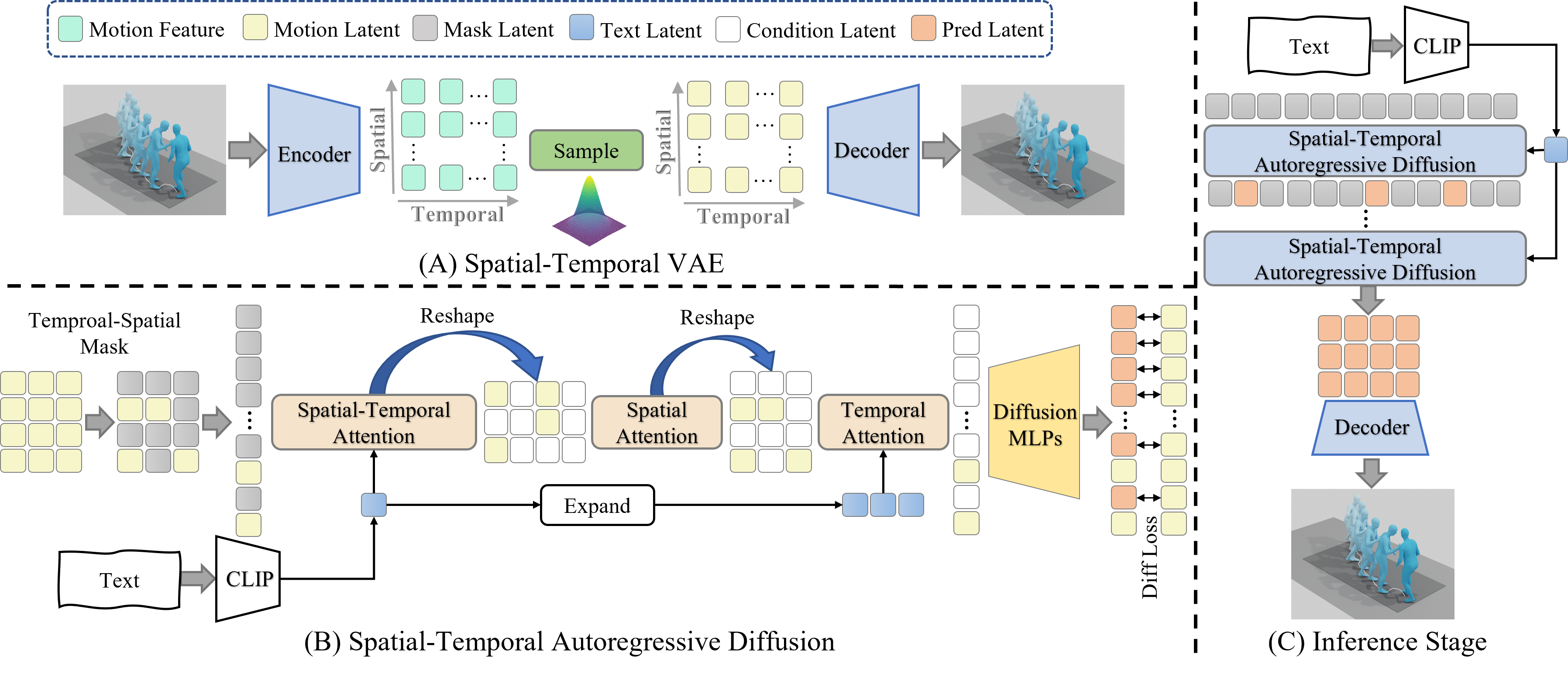
(A) Spatial-Temporal VAE encodes motion into 2D latent and decodes it for reconstruction. (B) Spatial-Temporal Autoregressive Diffusion includes Spatial-Temporal Attention, Spatial Attention and Temporal Attention and is trained via mask modeling, using a diffusion head to predict motion latent. (C) During inference, Spatial-Temporal Autoregressive Diffusion iteratively predicts the latent representations, which are subsequently decoded into the corresponding motion sequence.