


@@InProceedings{Chen_2026_CVPR,
author = {Chen, Zhuo and Yang, Chengqun and Su, Zhuo and Lv, Zheng and Gao, Jingnan and Zhang, Xiaoyuan and Yang, Xiaokang and Yan, Yichao},
title = {POLAR: A Portrait OLAT Dataset and Generative Framework for Illumination-Aware Face Modeling},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2026},
pages = {28871-28881}
}Abstract

Face relighting aims to synthesize realistic portraits under novel illumination while preserving identity and geometry. However, progress remains constrained by the limited availability of large-scale, physically consistent illumination data.
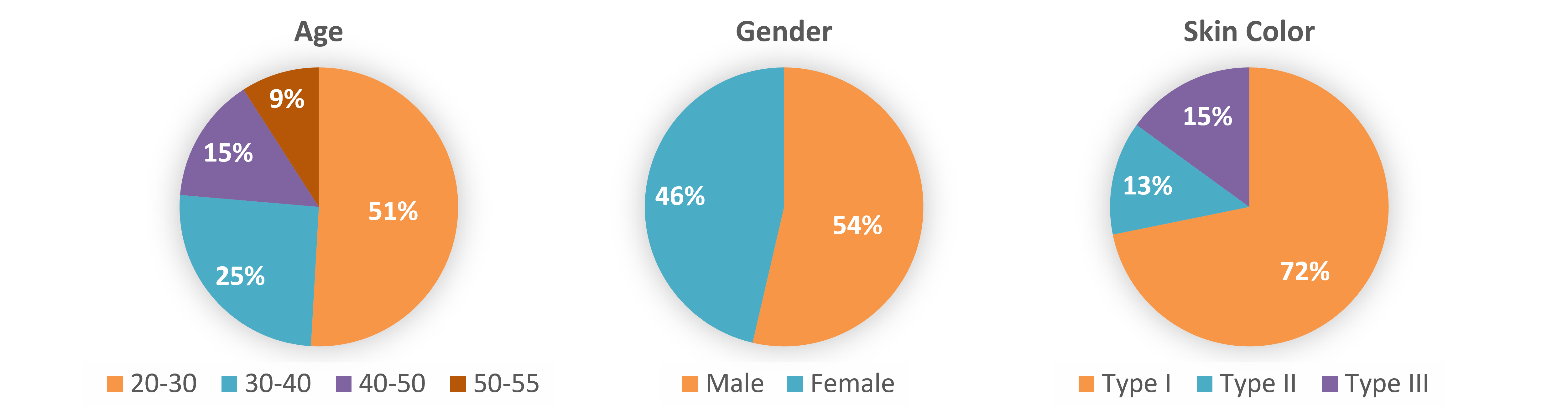
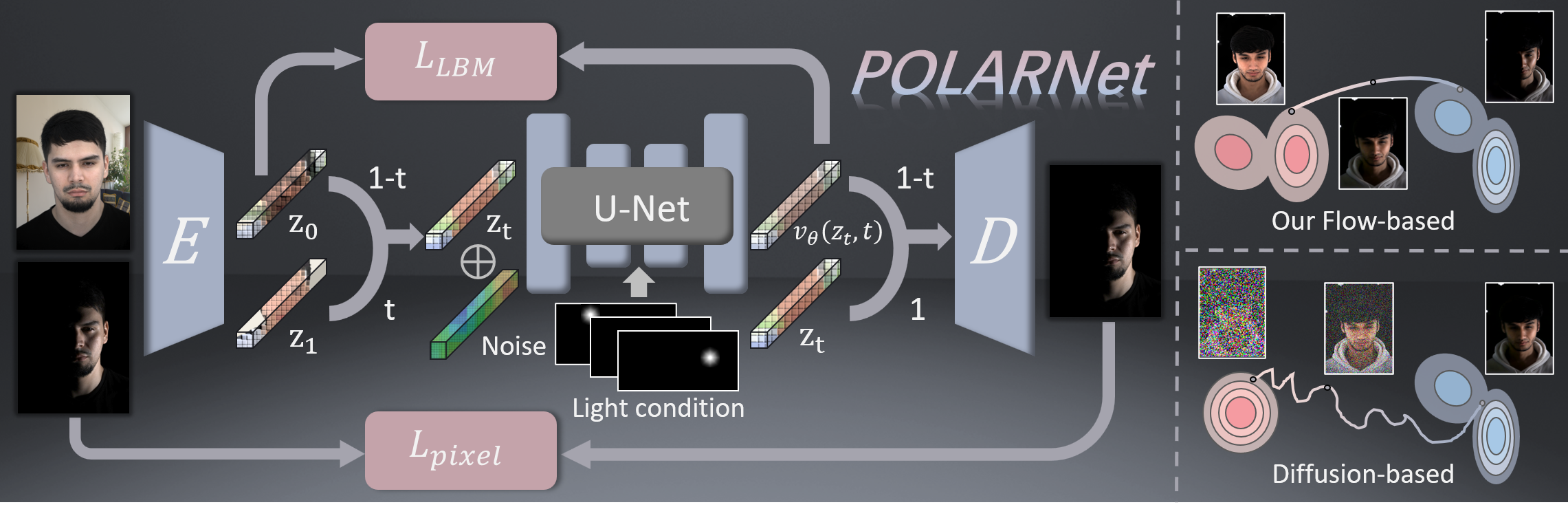
To address this, we introduce POLAR, a large-scale and physically calibrated One-Light-at-a-Time (OLAT) dataset containing over 200 subjects captured under 156 lighting directions, multiple views, and diverse expressions. Building upon POLAR, we develop a flow-based generative model POLARNet that predicts per-light OLAT responses from a single portrait, capturing fine-grained and direction-aware illumination effects while preserving facial identity.
Unlike diffusion or background-conditioned methods that rely on statistical or contextual cues, our formulation models illumination as a continuous, physically interpretable transformation between lighting states, enabling scalable and controllable relighting. Together, POLAR and POLARNet form a unified illumination learning framework that links real data, generative synthesis, and physically grounded relighting, establishing a self-sustaining “chicken-and-egg’’ cycle for scalable and reproducible portrait illumination.